


Du kennst es selbst: Deine Website ist schon länger online, zeigt sich bei Google aber selten unter den ersten Suchergebnissen. Also los geht die eigene Google-Suche: “website seo optimieren”. Die Ergebnisse versprechen viel, doch was ist die Lösung? Brauche ich 7 Tipps oder 12 Regeln, um meine Seite SEO-fit zu machen? In diesem Artikel möchten wir dir keine begrenzte Anzahl an Tipps und Regeln geben, sondern einen Überblick. Deshalb findest du in diesem Artikel wichtige Schritte, die du bei der technischen Optimierung berücksichtigen solltest.
Technical SEO bzw. technische SEO ist ein Teilbereich der Suchmaschinenoptimierung, der den Fokus vor allem auf die technischen Optimierungsmöglichkeiten legt.
On Page (Technik)
Du hast viel Zeit darin investiert, die SEO Grundlagen auf deiner Website umzusetzen, aber dein Ranking ist noch immer nicht so hoch wie gewünscht? Dann liegen bei deiner Seite wahrscheinlich noch Mängel in der technischen Umsetzung vor. Der Content einer Website kann noch so toll sein – wenn Ladezeiten, URLs, Darstellung etc. nicht optimiert sind, wird ihn kaum ein User zu Gesicht bekommen.
Technische Rankingfaktoren
Core Web Vitals
Der wohl wichtigste technische Ranking-Faktor ist für Google schon immer die Ladezeit einer Website. Und das wird sich so schnell auch nicht ändern. Mit den steigenden Suchanfragen über mobile Geräte wird auch die Ladezeit einer Seite immer wichtiger. Niemand hat die Geduld ewig zu warten, wenn er oder sie unterwegs schnell die Antwort auf eine Frage sucht. Wer eine Suchmaschine verwendet, will seine Antwort in der Regel also schnell haben. Lädt eine Website zu langsam, springen Besucher ab. Und da die User Experience für Google eine sehr große Rolle spielt, möchte die Suchmaschine langsame Seiten nicht unter den ersten Suchergebnissen sehen. Seit Juni 2021 prüft Google mit den Core Web Vitals deshalb Qualitätsmerkmale, die die Nutzererfahrung einer Website widerspiegeln. Diese Kennzahlen (KPIs) messen Werte zur Ladezeit, Interaktion und visuellen Stabilität einer Seite.
- Largest Contentful Paint (LCP): Dieser Faktor misst die Ladezeit des größten Contents innerhalb des sichtbaren Bereichs, beispielsweise ein Video oder ein Bild. Diese Ladezeit ist erst abgeschlossen, wenn dieser Content vollständig geladen und voll funktionsfähig ist. Dieser Messwert liefert also quasi die Antwort auf die Frage: Wie schnell ist die Website ausgewachsen? Länger als 2,5 Sekunden sollte das nicht dauern.
- First Input Delay (FID): Nur weil man bereits mit einer Website interagieren kann, heißt das noch nicht, dass diese bereits auf Eingaben reagiert. Die Dauer zwischen der ersten Interaktion des Users und der Reaktion des Browsers erfasst Google als den FID. Das sollte bei benutzerfreundlichen Websites weniger als 100 Millisekunden dauern.
- Cumulative Layout Shift (CLS): Man kennt sie leider: Webseiten, deren Komponenten beim Laden ständig verrücken. Bilder, die ganze Absätze verschieben oder Buttons, die die Position wechseln. Da so etwas die User Experience stark beeinträchtigt und gerade letzteres auch mal auf zwielichtigen Seiten zum ungewollten Kauf führt, straft Google Websites mit auffälligen Layout-Änderungen nun ab. Eine SEO-optimierte Seite ist für Google “visuell stabil”, wenn das Ergebnis der Berechnung (Impact Fraction x Distance Fraction = Layout Shift Score) unter 0,1 liegt.
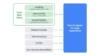
Quelle: Google
Jetzt musst du dich natürlich nicht mit einer Stoppuhr an den Rechner setzen. Mit der Google Search Console kannst du dir die Web Vitals Kennzahlen deiner Seite bequem auswerten lassen. Schnelle Abhilfe schafft auch das Tool Google Pagespeed Insights. So weißt du sofort, ob Verbesserungsbedarf besteht. Wie du die Werte optimieren kannst, erfährst du in diesem Artikel: Die Kernbereiche Crawling & Indexierung und Nutzerfreundlichkeit informieren über die häufigsten Fehler.
Mobile First Indexierung
Seit März 2021 streicht Google reine Desktop-Websites aus dem Index. Die Gründe dafür sind dieselben, die auch bei den Core Web Vitals genannt wurden – kurz gefasst also die Benutzerfreundlichkeit. Die Suchmaschine bevorzugt seit langem Seiten, die für mobile Nutzer:innen optimiert sind. Mit der Mobile First Indexierung geht Google also einen Schritt weiter: Nur noch mobil optimierte Webseiten werden indexiert. Ist deine Seite also noch nicht responsiv und für mobile Geräte optimiert, besteht spätestens jetzt Handlungsbedarf. Deine Seite ist in den Suchergebnissen nämlich nicht mehr zu finden.
In diesem Kontext sind vor allem besonders große, vielschichtige Seiten, genauso wie sogenannte m-dot Websites problematisch. Bei m-dot Websites handelt es sich um solche, die eine Desktop-URL und eine separate Mobile-URL haben. Die Mobile-URL sieht in der Regel so aus:
https://m.friendventure.com
Du hast also zwei URLs, die den gleichen Inhalt ausspielen, aber auf unterschiedliche Endgeräte optimiert sind. Sowohl für die Nutzerfreundlichkeit als auch für die Indexierung des Google Crawlers entstehen hier Nachteile.
Der Crawler unterscheidet zwar grundsätzlich nicht zwischen den URL-Formaten, allerdings solltest du dem Google-Algorithmus unbedingt die Beziehung der Desktop und Mobile-Variante der Websites signalisieren.
Google empfiehlt, das Verhältnis der beiden URLs mit Hilfe eines <link> Tags sowie rel=“canonical“ und rel=“alternate“ Elementen zu signalisieren.
Google unterstützt diese Anmerkungen auf zwei Varianten: Einerseits in der HTML der Seiten selbst oder in der Sitemap. Mehr Informationen und Beispiele findest du im Google Developers Blogbeitrag.
Wie schon hier erläutert, gibt es also durchaus Möglichkeiten, dem Googlebot beide URLs zu signalisieren und das Crawlen zu ermöglichen. Dennoch macht es aus aktueller Sicht immer Sinn, auf ein Responsive Webdesign umzusteigen oder zukünftige Websites responsive aufzubauen.
Professioneller SEO-Partner gesucht?
Wir unterstützen dich bei allen Schritten für erfolgreiches SEO – von technischen Maßnahmen bis zu einer langfristigen Content-Strategie.
Crawling & Indexierung
Damit du das Crawling und die Indexierung deiner Website oder bestimmten Unterseiten verbessern kannst, solltest du unbedingt den Kontext verstehen. Welche Seiten sollen überhaupt indexiert werden und welche wiederum nicht? Welche sollen gezielt vom Crawler ausgeschlossen werden und welche fordern besondere Aufmerksamkeit? Hier ist es zunächst sinnvoll zu verstehen, was der Unterschied zwischen Crawling und Indexierung ist.
Indexierung: Bedeutet die Gesamtheit aller von Google gespeicherten Seiten
Crawling (auch Bots genannt): Sind alle von Google erkannten Seiten
Wie kann ich eine Seite zur Indexierung hinzufügen?
Das geschieht am einfachsten mit der Google Search Console. Hier hast du die Möglichkeit, eine ganze Sitemap an Google zu schicken oder auch nur einzelne Seiten, die du gezielt definierst. Wie du die Google Search Console einrichtest und welche Vorteile du dadurch erhältst, erklären wir dir in einem separaten Abschnitt.
Wie kann ich verhindern, dass eine Seite indexiert wird?
Im ersten Moment fragt man sich wahrscheinlich, warum man überhaupt eine Seite von der Indexierung ausschließen sollte. Jedoch gibt es dafür legitime Gründe, die gelegentlich auftreten können.
- Eine Seite ist noch nicht fertiggestellt oder befindet sich gerade im Prozess eines Relaunch.
- Es handelt sich um eine Unterseite, die den Usern keinen Mehrwert bietet.
- Eine Seite oder Website ist lediglich zum privaten Gebrauch bestimmt und soll daher nicht in die SERP gelangen.
Um diese Seiten nun von der Indexierung auszuschließen, gibt es drei gängige Methoden:
- robots.txt: Somit kannst du den Crawler von Seiten gezielt aussperren. Wie du robots.txt gezielt anwendest, erfährst du später.
- Meta-Tag “noindex”: Mit diesem Meta-Tag bekommt der Google Crawler die Anweisung, eine Seite nicht zu indexieren. Das wird in der Regel von den Suchmaschinen berücksichtigt, ist aber am Ende immer nur eine Anweisung und kein Befehl. Der Meta-Tag sieht dann so aus:
<meta name=”robots” content=”noindex”/> - .htaccess: Hiermit bekommst du die Möglichkeit, den Crawler auszuschließen, indem du eine ganze Website oder einzelne Unterseiten mit Passwörtern schützt. Das ist eine gängige Methode, die auch von Google selbst empfohlen wird.
<meta name=”robots” content=”noindex”/>
Klicktiefe prüfen
Eine weitere Herausforderung für den Googlebot entstehen bei zu tief liegenden Seiten. Dabei handelt es sich konkret um Seiten, bei denen User viele Klicks benötigen, um von der Startseite auf eine gewünschte Unterseite benötigen – dabei wird immer nur der schnellste Weg berücksichtigt.
Als Richtlinie stellen Seiten besonders dann Probleme dar, wenn sie tiefer als zwei Klicks gehen. Das gilt vor allem für Seiten, die öfter gecrawlt werden sollen. Seiten, die drei Klicks oder mehr von der Homepage entfernt sind, erzielen in der Regel niedrigere organische Suchergebnisse. Das liegt vor allem daran, dass die Suchmaschine anhand des zugewiesenen Crawling-Budgets Schwierigkeiten hat, tief in die Seitenhierarchie einzutauchen. Daher dient eine Sitemap als sinnvolle Übersicht, wie die Seitenhierarchie deiner Website aussieht.
Sitemaps verwenden
Eine Sitemap ist – wie der Name schon sagt – ein Navigationstool für deine Website. Mit ihr soll schnell ermittelt werden können, wie viele Seiten und Unterseiten zu einer Website gehören. Wie bei vielen anderen Maßnahmen gilt das sowohl für Seitenbesucher:innen als auch für Bots. Besonders ist hier jedoch, dass Sitemaps für beide jeweils unterschiedlich aussehen.
Für menschliche Besucher:innen schafft die HTML-Sitemap Überblick. Sie funktioniert im Grunde wie eine Navigationsleiste, stellt aber eine eigene HTML-Seite dar und führt alle Seiten und Unterseiten der Website auf. Gerade auf umfangreichen Websites kann dies für Besuchende hilfreich sein.

Oben zu sehen ist ein Ausschnitt der HTML-Sitemap von ebay. In dieser finden sich alle großen Produktkategorien samt Unterkategorien. Verlinkt ist diese Seite – das ist eine gängige Konvention – im Footer unter “Übersicht”.
Für Bots auf der anderen Seite sind die sogenannten XML-Sitemaps gedacht. Diese werden zwar auf dem Webserver deiner Seite abgelegt, werden Besucher:innen jedoch nicht als Teil der Website angezeigt. In der Regel kannst du sie über URL-Endungen wie /page-sitemap.xml erreichen.
Solltest du noch keine Sitemap haben und WordPress benutzen, können wir dir dafür Yoast SEO ans Herz legen. Das Plug-In generiert die Sitemaps für deine Website automatisch. Zur Veranschaulichung zeigen wir dir gerne zwei unserer Sitemaps:


Die erste XML-Datei listet unsere Unterseiten auf, unsere Blogartikel aber zum Beispiel nicht. Diese befinden sich nämlich auf der Sitemap mit der Endung /post-sitemap.xml wieder. “Augenblick!”, wirst du jetzt vielleicht denken. “Wozu brauche ich denn mehrere Sitemaps?” Die Antwort darauf ist simpel: Du möchtest es dem Crawler so einfach wie möglich machen, deine Seiten auf den Index zu setzen. Wenn du diese für ihn bereits in Pages, Posts, Kategorien usw. sortierst hast – umso besser!
Auf die Spitze getrieben wird dies im zweiten der beiden Links. Bei diesem “sitemap_index” handelt es sich quasi um eine Sitemap für Sitemaps.
Interne Verlinkungen
Der Googlebot-Crawler, der deiner Seite indexiert, arbeitet sich von Link zu Link durch deine Website und speichert die gefundenen Informationen auf dem Google Server ab. Daher sind interne Links so vorteilhaft: Du kannst selbst entscheiden, wo die Links auftauchen, wie sie beschriftet sind und wie oft sie auftreten. So kannst du die Links genau so benennen, wie du es dir schon immer gewünscht hast und läufst gleichzeitig nicht Gefahr, von Google-Filtern abgestraft zu werden. Und nicht nur für das Crawling und die Indexierung sind interne Verlinkungen wertvoll, sondern auch für die Usability. So werden Nutzer:innen intuitiv und logisch von einem Thema oder Produkt zum nächsten geleitet.
Canonicals
Bei Canonicals handelt es sich um Tags für den HTML-Head einer Website, die so aussehen:
<link rel=“canonical“ href=“https://www.unternehmenxyz.de/unterseitexyz“ />
Dem Crawler wird so vermittelt, dass der Inhalt der URL im Canonical der Original-Inhalt ist und nur dieser indexiert werden soll. Die Originalseite verweist im Canonical auf sich selbst. Zu beachten ist, dass pro Seite natürlich nur ein Canonical verwendet werden darf – bei mehreren ignoriert der Crawler sie allesamt.
Dies funktioniert bei ähnlichen Sprachversionen übrigens genau so. Hast du von einer Seite mehrere Versionen für Deutschland, Österreich und die Schweiz, dann unterscheiden sich diese womöglich nur in der Rechtschreibung und der ein oder anderen Bezeichnung. Auch hier kannst du ein Canonical-Tag verwenden, um dem Crawler die Originalseite zu kennzeichnen: hrflang.
URLs und 301-Weiterleitungen
Eine weniger offensichtliche Form von Duplicate Content bilden Inhalte, die über mehrere URLs erreichbar sind. Dies macht man in der Regel, damit eine Seite auch über leicht abweichende Schreibweisen der URL erreichbar ist. Also z. B.:
- www.friendventure.de/blog/
- friendventure.de/blog/ (ohne www.)
- friendventure.de/blog (ohne Trailingsslash)
- https://www.friendventure.de/blog/ (SSL-verschlüsselt)
- http://www.friendventure.de/blog/ (nicht SSL-verschlüsselt)
In den obigen Fällen ist die gängige und beste Lösung die 301-Weiterleitung (301-Redirect). Damit leiten alle URLs auf die “wahre” Seite weiter. Der Crawler versteht, dass diese Weiterleitung dauerhaft ist und nimmt die weiterleitenden URLs vom Index, das heißt der Crawler sieht sie nicht mehr als mögliche Suchergebnisse. Dies ist jedoch nicht immer möglich, wenn beispielsweise
- eine Druck- bzw. PDF-Version einer Seite vorliegt oder
- mit dynamischen URLs gearbeitet wird,
gibt es zwar eine “Originalseite”, aber die anderen URLs sind trotzdem eigenständig und können nicht einfach zu Weiterleitungen umfunktioniert werden. In diesem Fall musst du Google auf andere Weise mitteilen, dass nur eine URL indexiert werden soll.
robots.txt prüfen
Damit nicht jede Seite von Suchmaschinenbots gelesen wird, gibt es die sogenannte “robots.txt”-Datei. Dabei handelt es sich um eine einfache Text-Datei, die ausgewählten Bots Berechtigungen erteilt, welche Seiten gecrawlt werden dürfen. Die Datei kann bei den meisten Websites ganz einfach eingesehen werden, indem man folgendes in die Suchleiste eingibt:
www.namederwebsite.de/robots.txt
Unsere robots.txt sieht zum Beispiel so aus:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Das Sternchen hinter User-Agent bedeutet, dass wir keinem einzigen Bot erlauben, unser Verzeichnis WP-Admin zu crawlen, mit Ausnahme der php-Datei “admin-ajax”. Dabei ist wichtig zu wissen, dass ein solches Verbot die Crawler nicht per se davon abhalten kann, eine Seite zu indexieren. Während sich die Bots der großen Suchmaschinen in der Regel daran halten, kann sich theoretisch jeder Bot darüber hinwegsetzen. Gerade Bots mit schlechten Absichten werden die robots.txt-Datei einfach ignorieren.
Nutzerfreundlichkeit optimieren
Strukturierte Daten
Damit deine Seite in den Ergebnissen einer Google Suche erscheint, muss Google die Inhalte auf relevanten Seiten verstehen. Hier kommen strukturierte Daten in Spiel: Sie helfen Google dabei, deine Seite zu erkennen und in den Suchergebnissen anzuzeigen. Der Vorteil von strukturierten Daten ist, dass sie die standardisierte Form sind, um Informationen zu einer Seite anzugeben und Seiteninhalte zu klassifizieren. Es gibt also klare Anweisungen, wie strukturierte Daten umgesetzt werden sollen, damit Google die Inhalte auf deiner Seite erkennt. Handelt es sich bei dieser Seite beispielsweise um ein Angebotsportfolio einer Agentur, kann Google Angaben, wie WordPress Relaunch, Google Ads, Erklärvideos uvm., erhalten.
Welche Vorteile bieten strukturierte Daten für die Google-Suchergebnisse?
Vor allem bietet sich der Vorteil, dass deine Seite öfter in Suchergebnissen erscheint und von relevanten Suchanfragen gefunden wird. Außerdem werden anhand strukturierter Daten spezifische Suchmaschinenergebnisfunktionen freigeschaltet. Beispielsweise kann deine Seite so in den grafischen Suchmaschinenergebnissen, in der Eventübersicht oder im FAQ-Bereich erscheinen. Das ist natürlich abhängig davon, welcher Inhalt sich auf der jeweiligen Seite befindet.
Der FAQ Bereich bei der Suchanfrage “api key erstellen google maps” sieht beispielsweise so aus:
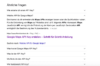
Anhand strukturierter Daten werden verschiedene Inhalte einer Seite mit Labels markiert, die dann wiederum dabei helfen, die Seite anhand relevanter Schlagwörter in den Suchergebnissen anzuzeigen.
Wie werden strukturierte Daten implementiert?
Sie werden mithilfe des In-Page-Markup auf deiner Seite codiert, damit Google die Inhalte der gewünschten Seite versteht. Folgende Formate werden von Google bei strukturierten Daten unterstützt: JSON-LD (von Google empfohlen), Mikrodaten und RDFa. Wie du strukturierte Daten auf deiner Seite implementierst, kannst du in der Google-Anleitung nachlesen.
Während der Erstellung strukturierter Daten ist das Tool für Rich-Suchergebnisse hilfreich. Einerseits kannst du während des Prozesses der Erstellung deine strukturierten Daten immer wieder testen und nach Fertigstellung anhand Statusberichten observieren. Somit hältst du die Qualität deiner strukturierten Daten immer im Blick.
Datenverkehr per SSL verschlüsseln
In Zeiten der DSGVO eigentlich selbstverständlich, aber wir wollten es trotzdem nochmal erwähnen: Beim Google-Crawler geht Sicherheit vor! Der Datenverkehr zwischen deiner Website und Nutzenden sollte darum per SSL-Zertifikat verschlüsselt sein. Wenn du dir nicht sicher bist, wirf einen Blick auf die URL deiner Seite. Steht am Anfang https? Dann kannst du beruhigt aufatmen. Wenn dem http noch das s fehlt, besteht Handlungsbedarf. Setze dich am besten mit deinem Webhoster auseinander – der sollte dir das Zertifikat zur Verfügung stellen.
BITV – Barrierefreiheit / Usability
Das Ziel der Barrierefreien-Informationstechnik-Verordnung (BITV) ist, eine umfassend und “grundsätzlich uneingeschränkt barrierefreie Gestaltung moderner Informations- und Kommunikationstechnik zu ermöglich und zu gewährleisten” (BITV, 2011). Anders gesagt, bildet das BITV eine Grundlage für Menschen mit Behinderung, Websites uneingeschränkt nutzen zu können. Daraus entstehen selbstverständlich besondere Anforderungen, die Websitebetreiber:innen erfüllen müssen. Öffentliche Stellen sind sogar dazu verpflichtet, ihre Informationen und Dienstleistungen barrierefrei zur Verfügung zu stellen.
Um zu testen, wie barrierefrei deine Website ist, bietet das BITV einen eigenen Test an, das aus zwei Schritten besteht. Im ersten Schritt wird der Status Quo der Website hinsichtlich der Barrierefreiheit ermittelt. Daraus wird ein Bericht generiert, der Hinweise auf Schwachstellen und Best Practices beinhaltet. Nach Anpassung dieser Hinweise wird im zweiten Schritt die Website ein zweites Mal überprüft und bestätigt im Idealfall, dass die Website nun barrierefrei bedient werden kann.
Ein weiterer, vom BITV unabhängiger Test, ist der Crazy Egg Test. Dieser Test ermöglicht dir, deine Website auf Benutzerfreundlichkeit zu testen und herauszufinden, wie unkompliziert und barrierefrei deine Seite nutzbar ist. Somit erhältst du hier einen umfassenderen Einblick in die Barrierefreiheit und kannst sie im Kontext von weiteren Faktoren der Benutzerfreundlichkeit bewerten. Der Crazy Egg Test ist in vollem Umfang kostenpflichtig, bietet allerdings einen 30 tägigen kostenlose Testphase an, in der du die Funktionalität ausprobieren kannst.
Wenn du Unterstützung bei der Gestaltung einer barrierefreien Website benötigst, sind wir der richtige Partner an deiner Seite.
Optimierungen für Mobile Geräte
Bevor du dich in der Tiefe mit der Optimierung deiner Website für mobile Geräte beschäftigst, kannst du sie prüfen und deinen Status Quo ermitteln. Dafür kannst du den Test auf Optimierung für Mobilgeräte von Google nutzen. Damit bekommst du einen Hinweis auf den aktuellen Stand deiner Website und gleichzeitig Hinweise, in welchen Bereichen sie noch optimiert werden kann.
Responsive Design
Ein erheblicher Teil des Internet-Traffics läuft heutzutage über mobile Endgeräte ab. 2018 gingen weltweit bereits 52,2 % aller Websiteaufrufe von mobilen Endgeräten aus – Tendenz steigend. Darum verfolgt Google mittlerweile den Mobile-First-Ansatz und crawlt vorwiegend die mobile Version einer Website. Somit ist Responsiveness zu einem extrem wichtigen Ranking-Faktor geworden. Zurecht! Denn wenn ein User heute eine Website auf seinem Handy öffnet und erst hineinzoomen muss, um auch nur ein Wort lesen zu können, dann ist das alles andere als nutzerfreundlich.
Sollte deine Seite auf Smartphones und Tablets genauso dargestellt werden wie auf dem Desktop, dann ist jetzt die Zeit gekommen, den Sprung zu wagen. Das wird nicht nur Google, sondern auch deine Kunden freuen! Die Umsetzung kann aber viel Zeit und technisches Knowhow beanspruchen – je nachdem wie alt deine Seite ist oder mit welchem System sie umgesetzt wurde. Auch wenn es nicht danach klingt: Ein Relaunch, also das vollständige Redesign und Neuaufsetzen der Website, ist hier meist die einfachste Lösung. Wenn du dabei Hilfe brauchen solltest, stehen wir dir gerne zur Verfügung!
Seitenladezeit / Pagespeed
Die Seitenladezeit einer Website ist schon seit einigen Jahren einer der wichtigsten Faktoren, auf den Google Wert legt. Mittlerweile ist sie nicht mehr nur ein Rankingfaktor, sondern elementarer Bestandteil der Usability einer Website. Weitere Grundlagen zum Thema Pagespeed sowie eine detaillierte Anleitung, wie du anhand unterschiedlicher Tools die Seitenladezeit deiner Website prüfen kannst, erfährst du in unserem separaten Blogartikel.
Lange Ladezeiten haben auch einen negativen Einfluss auf den Crawler des Googlebots. Auch Google will kosten- und ressourceneffizient arbeiten, wodurch der Bot ein Zeitlimit hat, das ihm zum crawlen deiner Website bereitsteht. Je schneller deine Pagespeed ist, desto mehr Seiten können in dieser Zeit indexiert werden.
Nutze PageSpeed Insights
Google selbst bietet einen Test an, mit dem du den Pagespeed deiner Website prüfen kannst. Er gibt dir einen Einblick in deinen Status Quo und Hinweise auf mögliche Schwachstellen deiner Seite. Allerdings solltest du diesen Test wirklich nur als Empfehlungstool sehen, denn die Google-Noten sind mit Vorsicht zu genießen. Google gibt nämlich keinen echten Geschwindigkeitswert aus, sondern lediglich ein Geschwindigkeitspotential, das sich an festgelegte Google-Kriterien hält. Für die Interpretation des Ergebnisses gilt: Google gibt Hinweise auf Maßnahmen, die die Performance deiner Website theoretisch optimieren. Ob diese Maßnahmen sinnvoll sind oder sich überhaupt umsetzen lassen, berücksichtigt Google nicht.
Entferne unnötigen Code / MINIFICATION DES QUELLCODES
Manche Seiten bestehen aus hunderten von Quellcode-Zeilen. Ist hier in jeder zweiten Zeile unnötiger Code, wird sich dies deutlich negativer auf die Ladezeit auswirken. Für Stylesheets oder Skripten gilt es daher, folgende Faktoren für die Ausführung zu überprüfen und diese dann ggf. zu löschen:
- Whitespace für Einrückungen (unnötige Leerzeichen)
- Kommentare im Quellcode
- lange Funktions- und Variablennamen
- unbenutzter Code
Technik-Profis gesucht?
Wir optimieren deine Website hinsichtlich Technik, UX und Content – für schnelle Ladezeiten, gute Sichtbarkeit und eine optimale Kundenerfahrung.
Optimiere Bilder
Es kommt oft vor, dass Bilddateien und Grafiken mehr als die Hälfte der Gesamtgröße einer Website einnehmen. Dabei gibt es einige Möglichkeiten, die Größe der Bilder stark zu reduzieren und dabei gleichzeitig die Ladegeschwindigkeit der Website zu beschleunigen:
- Wähle die richtige Datei: Besonders Bildformate wie JPEG 2000, JPEG XR und WebP bieten eine hochwertigere Komprimierung als PNG oder JPEG-Dateien an. Dadurch erreichst du schnellere Downloads und ermöglichst gleichzeitig einen geringeren Datenverbrauch.
- Nutze Plugins: WordPress bietet Plugins, die automatisch deine Bilder komprimieren.
- Speichere Dateien optimal: Nutzt du beispielsweise Photoshop zur Erstellung deiner Grafiken, kannst du sie mit “Speichern fürs Web” komprimiert abspeichern.
Verringere/Kürze HTTP-Anfragen
Eine hohe Anzahl an HTTP-Anfragen kann die Ladezeit einer Seite erheblich verlangsamen. Die logische Konsequenz: Eine schlechte User Experience, Einbußungen im Suchmaschinenranking und eine hohe Bounce Rate der Besucher:innen deiner Website.
Was sind HTTP-Anfragen?
HTTP-Anfragen sind Anfragen, die der Webbrowser des Seitenbesuchenden an den Server stellt, um Informationen über eine Seite zu bekommen. Gelangt eine Besucher:in auf deine Website, beachtet der Server diese Anfrage und schickt die auf der Seite enthaltenen Dateien an den Browser der Benutzer:in zurück. Es gilt: Je weniger dieser HTTP-Anfragen eine Website stellen muss, desto schneller kann eine Seite geladen werden.
Wie kann die Anzahl der HTTP-Anfragen reduziert werden?
Mehr Dateien bedeuten mehr HTTP-Anfragen: Der Webbrowser muss für jede einzelne Datei einer Website eine HTTP-Anfrage stellen. Die meisten guten Websites haben viele Dateien. Daher solltest du einige Möglichkeiten beachten, um die Ladezeit deiner Website positiv zu beeinflussen.
- Nutze gMetrix: gMetrix bietet dir einen Überblick über den aktuellen Stand deiner Website. Hier bekommst du einen Überblick über verschiedene Kennzahlen deiner Website, wie SEO, Gesamtdateigröße, aber auch die Anzahl der HTTP-Anfragen.
- Nutze die “Untersuchen” Funktion bei Google Chrome: Finde so heraus, welche Dateien auf deiner Website am größten sind und am längsten laden. Hier bekommst du einen weiteren hilfreichen Einblick, welche Dateien optimiert werden sollten.
- Lösche unnötige Bilder: Und dabei vor allem solche, die besonders viel Speicherplatz einnehmen
- Reduziere die Größe der restlichen Bilder: Um Zeit zu sparen, helfen hier Plugins von WordPress.
- Lade JavaScript-Dateien asynchron: Renderblocking bedeutet, dass JavaScript Dateien nach für nach auf einer Seite lädt. Selbst wenn der Browser eines Nutzenden mehr als eine HTTP-Anfrage schickt, lädt der empfangene Inhalt Stück für Stück. Dadurch wird die Ladezeit einer Website oftmals verlangsamt, da jede Datei auf das Laden im Browser des Benutzenden wartet. Asynchrones Laden ermöglicht, dass Seitenelemente unabhängig voneinander angezeigt werden können. WordPress Plugins können auch hier die Arbeit erleichtern.
- CSS-Dateien miteinander komprimieren: Jede CSS-Datei auf einer Seite erhöht die Anzahl der HTTP-Anfragen. Das ist zwar einerseits unvermeidbar, dennoch gibt es oftmals Dateien, die miteinander kombiniert werden können. Das gilt für CSS-Dateien, die einander ähneln, sodass der Browser nur noch eine HTTP-Anfrage senden muss.
Nur ein CSS-Stylesheet verwenden
Auch beim Thema CSS-Stylesheet können Aspekte berücksichtigt werden, die mit einem guten Pagespeed belohnt werden. Mit CSS werden Schriftgröße, Farben und weitere Designelemente definiert. Wird jedoch jedes einzelne Element mit einem gesonderten CSS-Befehl oder HTML-Code hinterlegt, erfolgt für jeden Style eine neue Abfrage. Das wirkt sich schließlich negativ auf die Ladezeit einer Website aus. Der Browser schickt einen HTTP-Request für jede Datei, die in deinem HTML verlinkt ist und beim Aufruf deiner Seite geladen wird an den Web Server. Daraufhin sendet der Server wiederum einen Request der geforderten Dateien an den Browser zurück. Hier wird ganz klar deutlich: Je mehr Dateien in einem HTML-Dokument sind, desto mehr Anfragen finden statt, was wiederum den Pagespeed beeinträchtigt.
Was in diesem Fall hilft, ist alle Stylesheets (also CSS-Dateien) und alle benutzerdefinierten JavaScript-Dateien zu einer einzelnen Datei zusammenzufassen.
301-Umleitungen reduzieren
Vor allem solltest du überprüfen, dass deine 301-Umleitungen sauber eingerichtet sind. Leitet eine Umleitung auf eine weitere Umleitung um, die dich wiederum in einen endlosen Funnel führt, in der immer wieder versucht wird, eine Seite aufzurufen, dann stehst du vor einem Problem. 301-Umleitungen sollten immer direkt und ohne Umwege auf die Zielseite führen. Ansonsten entsteht ein herber Verlust des Pagespeed und der Usability deiner Seite.
Serverseitiges Caching verwenden
Serverseitiges Caching unterstützt dabei, häufig gesendete Anfragen auf dem Server zwischenzuspeichern. Dabei handelt es sich oftmals um Datenbank-Anfragen. Das ist besonders hilfreich für die User, die in einer Session mehrere Seiten aufrufen – sich beispielsweise mehrere Blogartikel oder unterschiedliche Produkte anschauen möchten. Das serverseitige Caching kann in diesem Fall Ladezeiten nach dem ersten Seitenaufruf verkürzen.
Das Caching lässt sich in den Einstellungen der Webserver-Software aktivieren und einrichten – in den meisten Fällen wird hier Apache HTTP Server und Nginx verwendet. Oftmals bieten Hosting-Anbieter hier ihre Unterstützung an, sollte dir das nötige Knowhow fehlen.
Das Laden unnötiger Dateien vermeiden
Hierbei liegt der Fokus vor allem auf den Daten, die vom Browser heruntergeladen werden, für die Darstellung der Website gar nicht relevant sind. Sie verlangsamen nämlich konsequent den Pagespeed deiner Website. Daher solltest du sicherstellen, dass auf der Seite auch wirklich nur das angezeigt wird,was für die User relevant ist.
Folgende Möglichkeiten verhindern das Laden unnötiger Dateien:
- Lazy Loading: stellt sicher, dass nur die Bilder heruntergeladen werden, die den Nutzer:innen angezeigt werden. Beispielsweise werden Bilder, die sich ganz unten auf einer Seite befinden, nur dann geladen, wenn die Nutzenden auch wirklich bis ganz nach unten scrollen. Glücklicherweise unterstützen die meisten modernen Browser das Lazy Loading nativ.
- Große CSS und JavaScript Bibliotheken: Bei besonders großen CSS- und JavaScript Bibliotheken kann es vorkommen, dass ein Teil der übertragenen Daten für die Website gar nicht benötigt werden. Diese können dann dementsprechend verkleinert werden.
- Code-Splitting: Code-Splitting wird oft von modernen Webanwendungen angeboten und bietet die Möglichkeit, den gesamten Code einer Website in verschiedene Bündel aufzuteilen. Diese wiederum können dann auf Abruf oder parallel zueinander laden. Das hilft dabei, große Bibliotheken, die eine enorme Dateigröße haben, aufzuteilen – dadurch entsteht eine Vielzahl an kleineren Dateien. Vor allem in der Kombination mit Lazy Loading ist das Code Splitting sinnvoll. Somit werden Dateien erst dann geladen, wenn der User sie abruft. Der Vorteil, der hier entsteht: Die totale Anzahl der Codes bleibt dieselbe aber der Code, der bei einem primären Ladevorgang benötigt werden, ist reduziert.
Kritische CSS Dateien priorisiert laden
Kritische CSS Dateien können priorisiert geladen werden und damit wiederum Ladezeit reduzieren. Hat man beispielsweise eine enorm große Anzahl an Schriftarten für eine Seite, dann sind wahrscheinlich nicht alle dieser Schriftarten immer relevant. In diesem Fall kann man die Haupt-Schriftart priorisieren, sodass diese zuerst lädt, damit der Text auf der Seite unmittelbar erscheint. Alle anderen, weniger notwendigen Schriftarten können dann im Hintergrund (und damit im zweiten Schritt) geladen werden. Somit muss keine große Datei auf einmal geladen werden, sondern sie werden priorisiert und vor allem nacheinander geladen.
Google Search Console einrichten
Die Google Search Console ist ein hilfreiches Tool, mit der du die Präsenz deiner Website in Google-Suchmaschinenergebnissen beobachten kannst und zusätzlich Einblicke in mögliche Fehlerquellen bekommst, die du direkt verwalten kannst.
Folgende Tools, Daten und Berichte stehen dir zur Verfügung:
- Informationen, ob Google die Website finden kann und crawlt.
- Hinweise auf Indexierungsprobleme und die Möglichkeit neue, aktualisierte Informationen anzufragen.
- Einsicht in die Google-Suchanfragedaten, wie oft deine Website in Google-Ergebnissen erscheint und darüber hinaus, welche Suchanfragen für deine Suchergebnisse relevant sind, wie hoch die Klickrate ist usw.
- Benachrichtigungen, wenn Google einen Fehler bei der Indexierung oder Spam und andere Probleme auftreten.
- Einen Überblick, welche anderen Websites auf die eigene verlinken.
- Hinweise auf Probleme, die mit AMP-Seiten, User Experience auf Mobilgeräten oder anderen Suchfunktionen entstehen.
Da die Google Search Console ein kostenloses Tool direkt von Google ist, verschafft es durchaus für jede Person einen Mehrwert, die Websiteinhaber:in ist oder regelmäßig mit einer Website arbeitet.
Technische SEO Fehler
- Technische SEO geschieht von heute auf morgen: Wie dieser Guide hoffentlich vermittelt, kann technische SEO nie von jetzt auf gleich umgesetzt werden. Denn dahinter verbergen sich zahlreiche Prozesse, komplexe Arbeitsschritte und immer wieder das generieren von umfangreichem Wissen.
- Technische SEO funktioniert auch ohne Expertise: Die Realität besagt genau das Gegenteil. Erfahrene Entwickler sind hier die optimale Lösung, denn sie kennen viele verschiedene Prozesse, haben sich das umfangreiche Wissen bereits angeeignet und können auf mögliche Herausforderungen souverän reagieren.
- Technische SEO findet unabhängig von anderen Bereichen statt: Technische SEO sollte nie isoliert betrachtet werden. Nutze auch andere Bereiche, wie Marketing oder Conversion-Optimierung, um deine SEO noch besser einzusetzen.
Fazit
Nachdem du nun unseren SEO-Guide für Einsteigende und diesen SEO-Guide für Fortgeschrittene fertig gelesen hast, hast du eine fundierte Wissensgrundlage, um von nun an sinnvolle und effiziente Suchmaschinenoptimierung zu betreiben. SEO ist und bleibt ein komplexer Prozess, der nicht morgen und auch nicht übermorgen abgeschlossen sein wird. Daher solltest du dich stets weiterbilden und SEO-Trends im Blick behalten und dazu bereit sein, Zeit und Ressourcen zu investieren. Dennoch sind wir überzeugt, dass du bei den ganzen Richtlinien und Guidelines nicht vergessen solltest, informativen und hochwertigen Content zu schreiben, der dich stolz macht. Auch das ist eine wertvolle Möglichkeit, deine User nachhaltig zu überzeugen. Eine professionelle SEO-Agentur unterstützt dich dabei, eine nachhaltige Content-Strategie zu erstellen sowie Inhalte, die sowohl Google als auch deine Kunden glücklich machen.
